

La plupart des formations de réseaux de neurones profonds reposent fortement sur la descente de gradient, mais le choix de la taille de pas optimale pour un optimiseur est difficile car il implique un travail manuel fastidieux et sujet aux erreurs.
Dans le document exceptionnel NeurIPS 2022 Descente de dégradé : l’optimiseur ultime, les chercheurs du MIT CSAIL et de Meta présentent une nouvelle technique qui permet aux optimiseurs de descente de gradient tels que SGD et Adam d’ajuster automatiquement leurs hyperparamètres. La méthode ne nécessite aucune différenciation manuelle et peut être empilée de manière récursive à plusieurs niveaux.
L’équipe répond aux limites des précédents optimiseurs de descente de gradient en activant la différenciation automatique (AD), qui offre trois avantages principaux :
- AD calcule automatiquement les dérivées correctes sans aucun effort humain supplémentaire.
- Il se généralise naturellement à d’autres hyperparamètres (par exemple le coefficient de quantité de mouvement) gratuitement.
- AD peut être appliqué pour optimiser non seulement les hyperparamètres, mais aussi les hyper-hyperparamètres, et les hyper-hyper-hyperparamètres, et ainsi de suite.
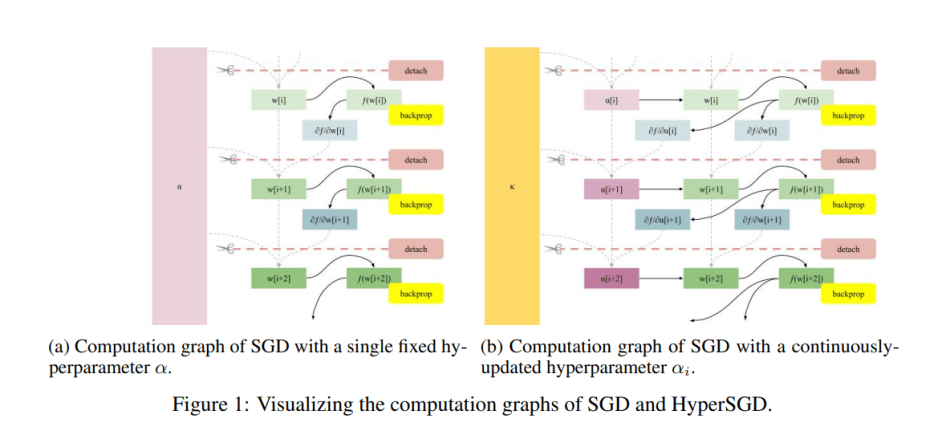
Pour permettre le calcul automatique des hypergradients, l’équipe “détache” d’abord les poids du graphe de calcul avant la prochaine itération de l’algorithme de descente de gradient, qui convertit les poids en feuilles de graphe en supprimant tous les bords entrants. Cette approche empêche le graphe de calcul de croître à chaque étape, ce qui entraînerait un temps quadratique et une formation insoluble.

L’équipe permet également au processus de rétropropagation de déposer des gradients en ce qui concerne à la fois les poids et la taille des pas en ne détachant pas la taille des pas du graphique, mais en détachant ses parents à la place. Cela conduit à un algorithme d’hyperoptimisation entièrement automatisé.
Pour permettre le calcul automatique des gradients via AD, les chercheurs alimentent de manière récursive HyperSGD lui-même en tant qu’optimiseur pour obtenir un hyperoptimiseur de niveau supérieur, HyperSGD. AD peut être appliqué de cette manière aux hyperparamètres, hyper-hyperparamètres, hyper-hyper-hyperparamètres, etc. Au fur et à mesure que ces tours d’optimisation grandissent, elles deviennent moins sensibles au choix initial des hyperparamètres.

Dans leur étude empirique, l’équipe a appliqué leur SGD hyperoptimisé à des optimiseurs populaires tels qu’Adam, AdaGrad et RMSProp. Les résultats montrent que l’utilisation de SGD hyperoptimisé améliore les performances de base par des marges significatives.
Ce travail introduit une technique efficace qui permet aux optimiseurs de descente de gradient d’ajuster automatiquement leurs propres hyperparamètres et peut être empilé de manière récursive à plusieurs niveaux. Une implémentation PyTorch de l’algorithme AD de l’article est disponible sur le site du projet GitHub.
Le papier Descente de dégradé : l’optimiseur ultime est sur OuvrirRévision.
Auteur: Hécate Il | Éditeur: Michel Sarazen

Nous savons que vous ne voulez manquer aucune actualité ou percée de la recherche. Abonnez-vous à notre populaire newsletter IA mondiale synchronisée hebdomadaire pour obtenir des mises à jour hebdomadaires de l’IA.



